AudioDAS
Distributed audio processing engine with extreme concurrency (threads, semaphores, channels), Edge AI in the browser, and efficient streaming (HTTP 206).
Project Overview
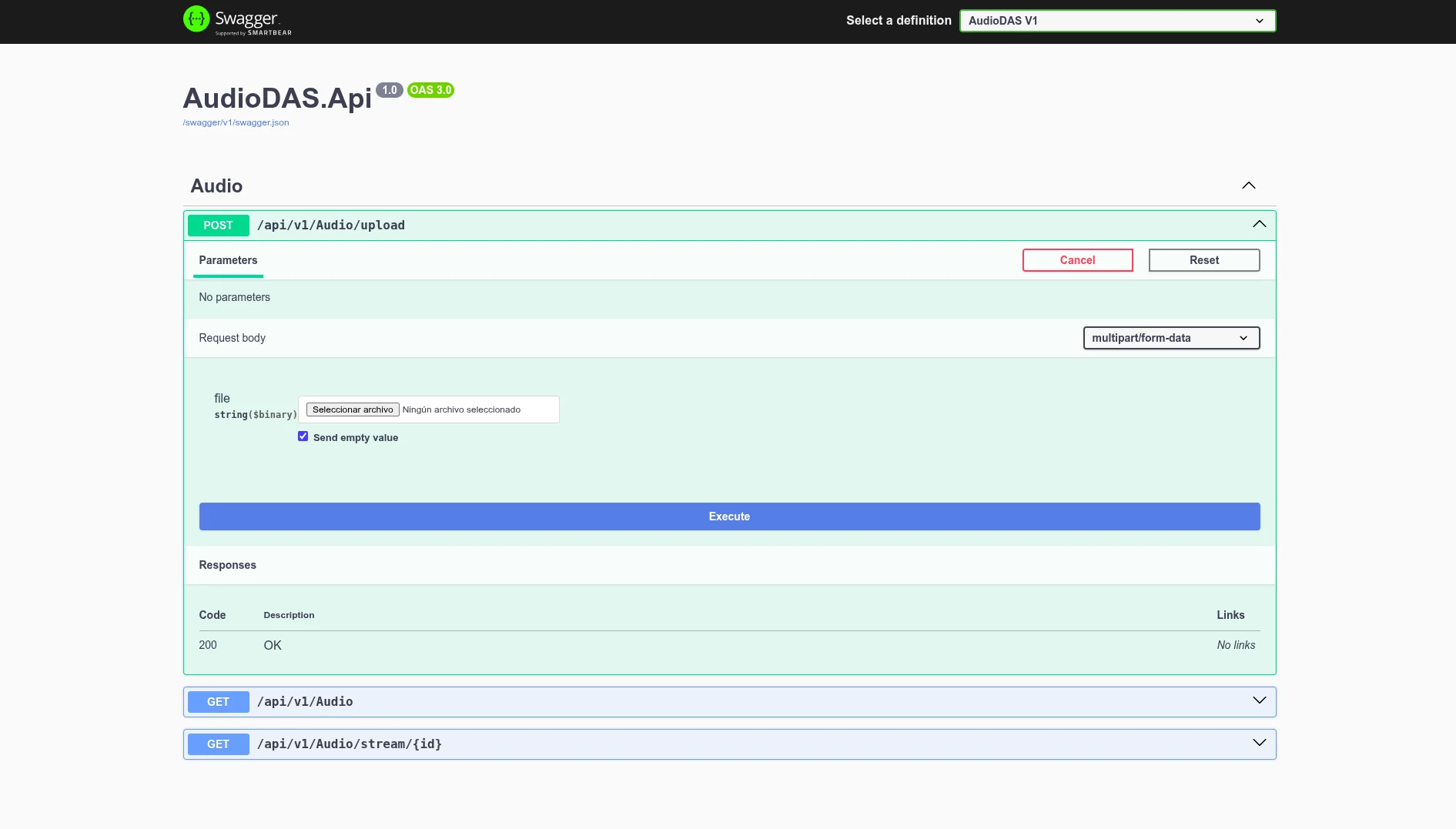
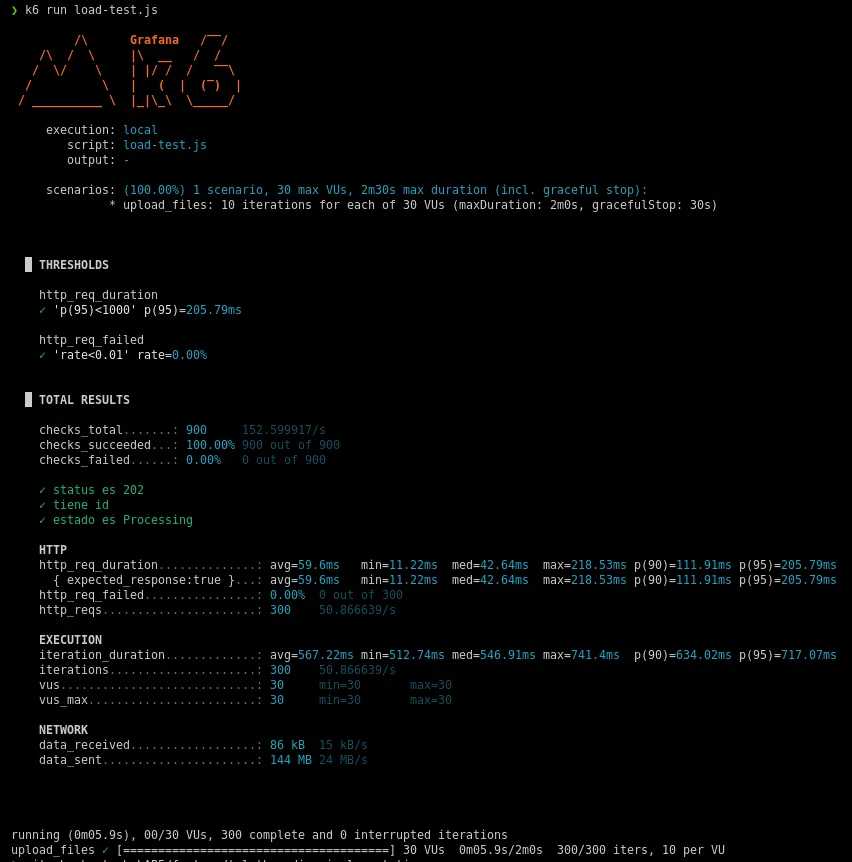
I designed and developed AudioDAS, the processing engine for a real Digital Assistance System. I implemented a Clean Architecture under a Modular Monolith in .NET 9. I optimized the server using the Task Parallel Library (TPL), the Producer-Consumer pattern with System.Threading.Channels, and SemaphoreSlim-based concurrency control to prevent CPU saturation. The system orchestrates multiple tasks in parallel: AAC compression with FFmpeg, audio filtering, and two consecutive Python subprocesses (Whisper + Flan-T5) for transcription and summarization. All of this achieved a p95 response time of 205ms and a 0% error rate under k6 stress tests. I also implemented Edge AI on the frontend (ONNX Runtime WebAssembly) to validate audio locally before uploading, dramatically reducing network traffic. Final streaming uses HTTP 206 Partial Content for instant playback without full downloads.
Architecture Design
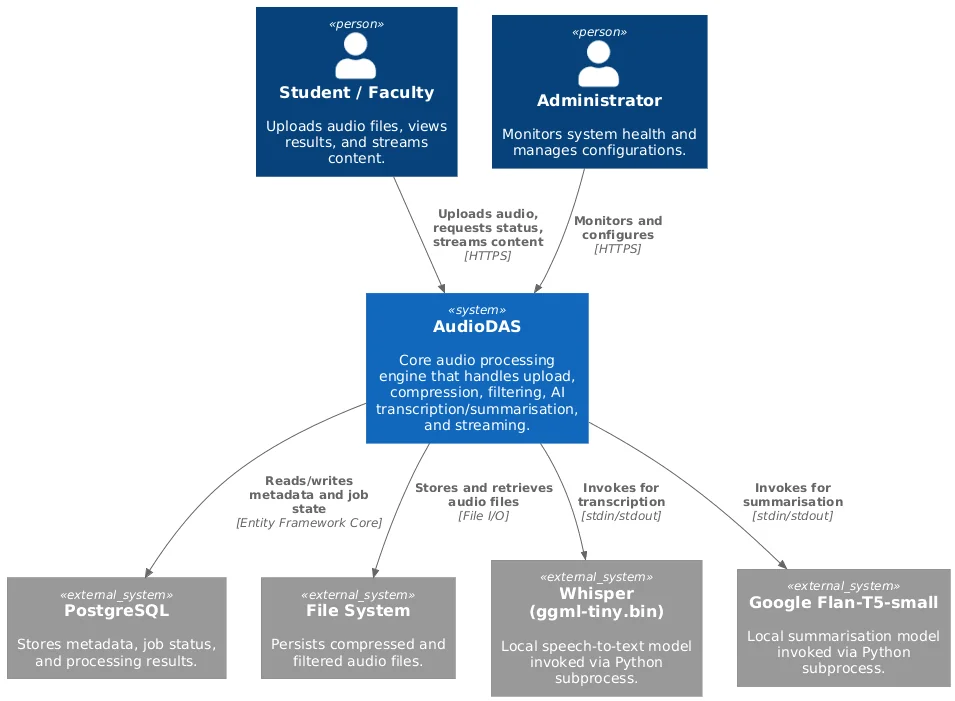
Context Diagram: Users, Frontend with Edge AI, .NET Backend, Workers, FFmpeg, and Python Models
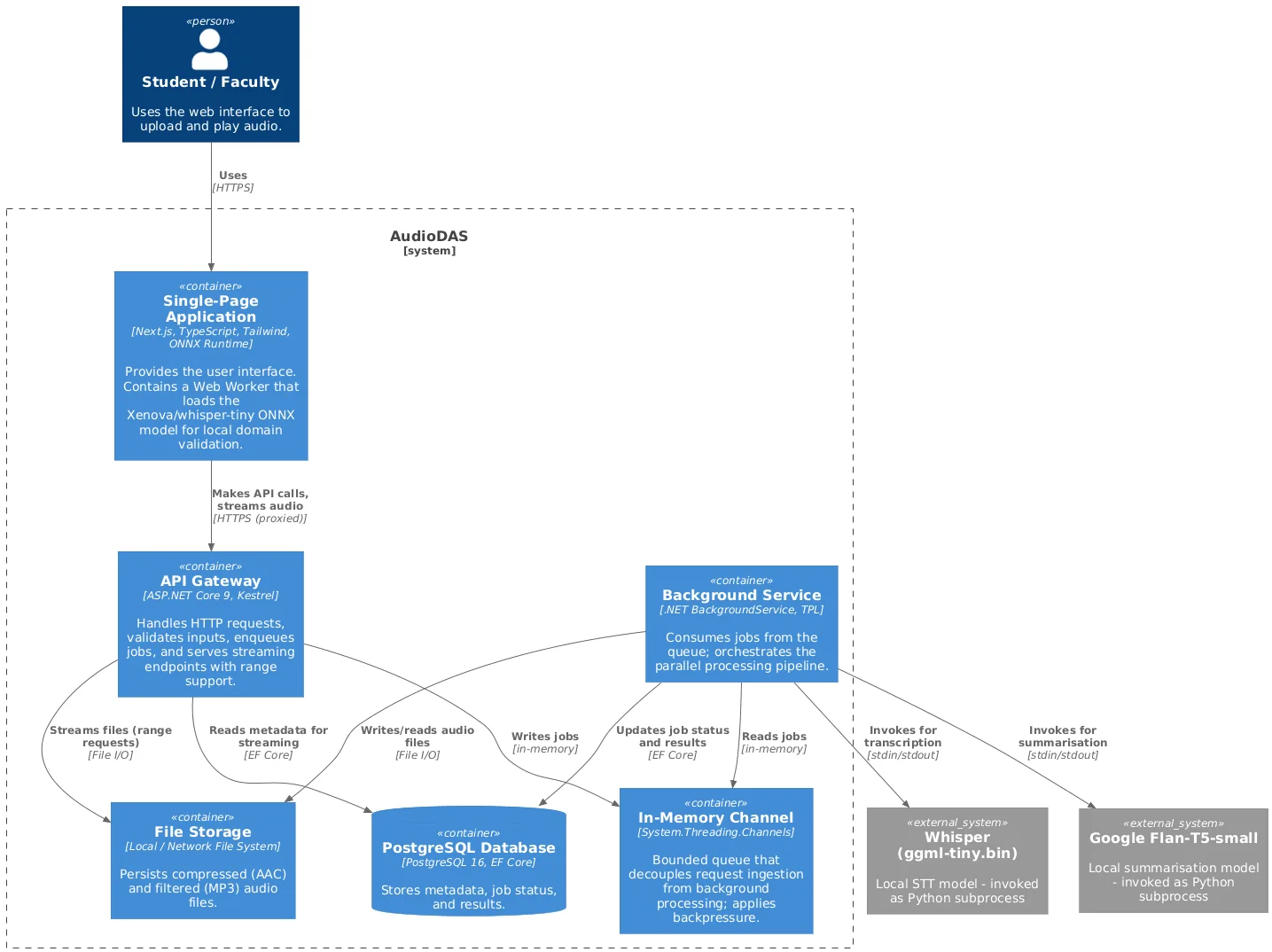
Container Diagram: .NET API, Background Worker, Channel, PostgreSQL, Python Subprocesses, and FFmpeg
Core Modules
Extreme Concurrency: Threads, Semaphores & Channels
Producer-Consumer pattern implemented with System.Threading.Channels for non-blocking task queuing. SemaphoreSlim (2-2-2 configuration) limits parallelism: max 2 simultaneous FFmpeg processes and 2 AI inferences. The worker consumes tasks and launches three parallel threads with TPL (Task Parallel Library), achieving audio compression and filtering in parallel with AI — without saturating the CPU or blocking HTTP requests.
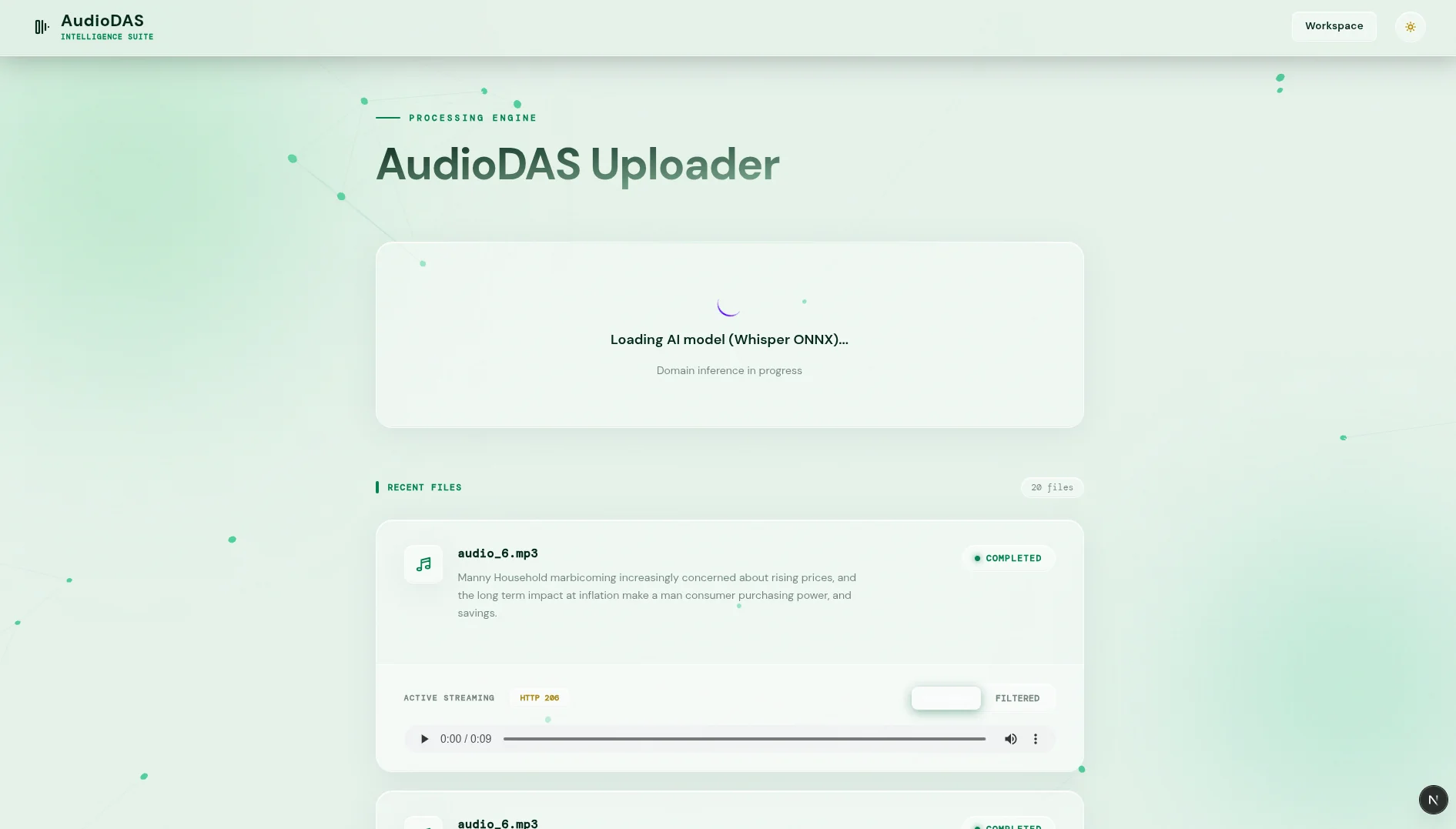
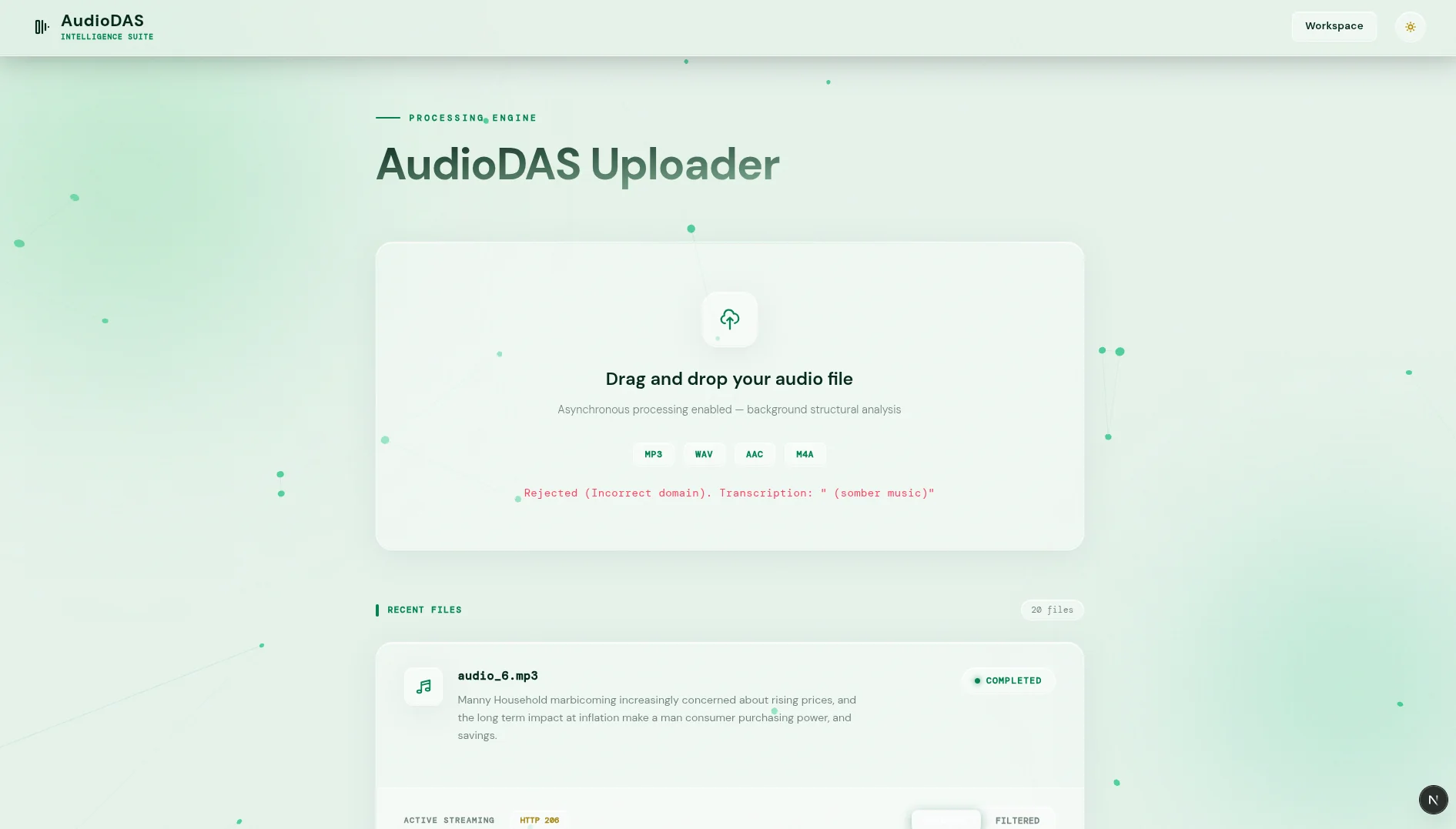
Edge AI on the Client: ONNX Runtime WebAssembly
The frontend (Next.js) runs the Whisper-tiny (ONNX) model inside a Web Worker. It decodes audio locally with AudioContext, transcribes it, and validates the domain (e.g. 'economics') before uploading. If invalid, the file is rejected on the spot; if valid, it's uploaded. This saves bandwidth and prevents the server from processing garbage.
Parallel Server Processing with Python Subprocesses
The main worker launches two sequential Python subprocesses: first Whisper (ggml-tiny.bin) for transcription, then Flan-T5-small for summarization. Both models are loaded once into RAM (Singleton) and run under the same AI semaphore, ensuring no more than two simultaneous inferences. The result is a 50-character summary optimized for metadata.
Compression & Normalization with FFmpeg (Concurrent)
Two independent tasks run FFmpeg in parallel: one compresses to AAC (for 5-year legal retention), the other applies an echo filter and produces filtered MP3. Both share a 2-instance semaphore, so the limit of heavy processes is never exceeded. The rest of the HTTP requests keep responding without waiting.
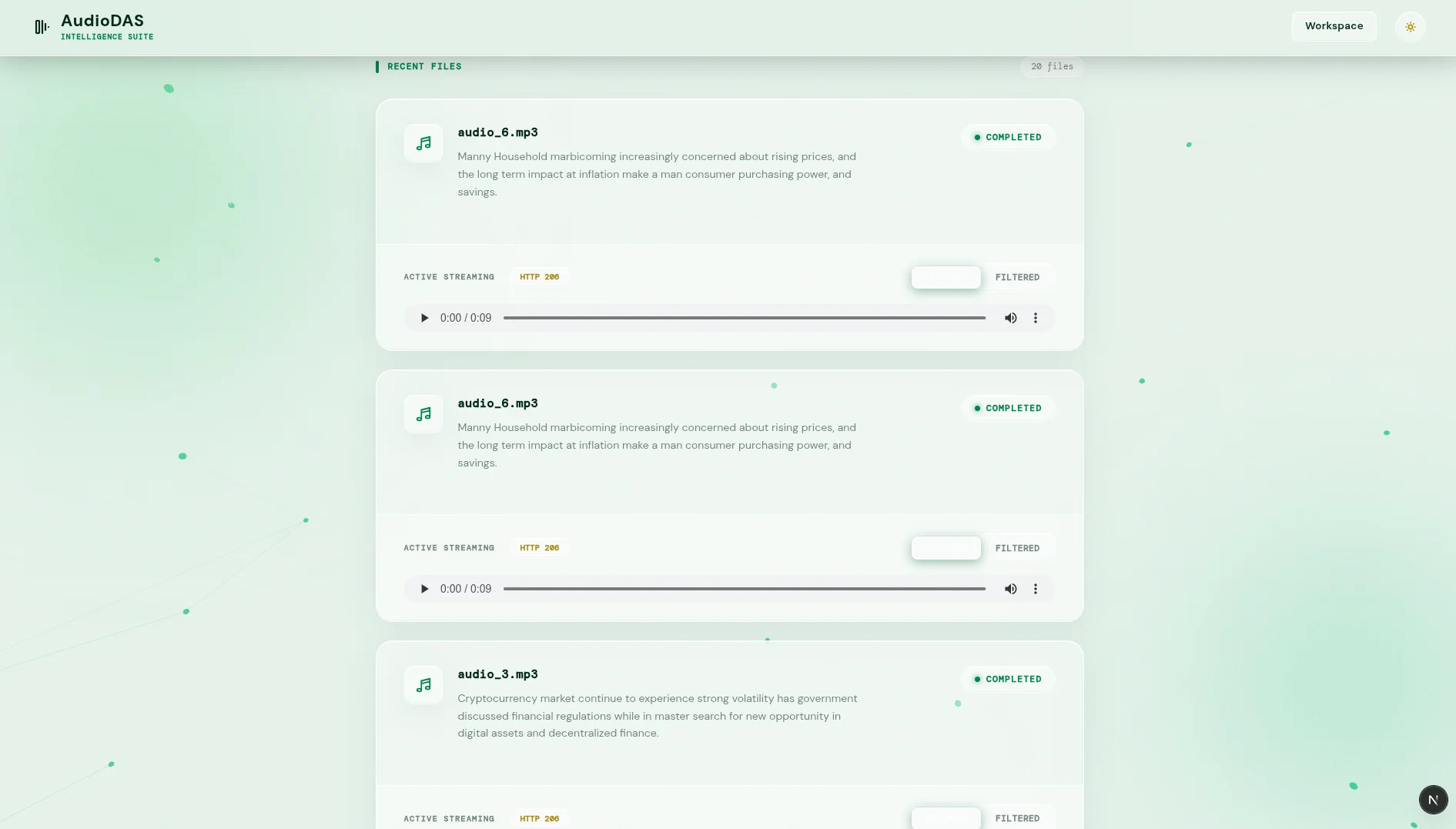
Smart Streaming with HTTP 206 Partial Content
The /stream endpoint supports the Range header and responds with 206 Partial Content and Accept-Ranges: bytes. The HTML5 player can request only the needed fragment (e.g. bytes=0- to start fast). On seek, the browser automatically generates new range requests, downloading only the necessary bytes without loading the full file.
Stress Testing & Concurrency Monitoring
k6 test suite that simulated 1000 concurrent users uploading files and streaming audio. Throughput, p95 latency (205ms), and semaphore usage were measured. Unit tests with xUnit, Moq, and FluentAssertions cover domain and application logic.
Containerized Infrastructure & Reproducible Deployment
Multi-stage Docker build with .NET 9 SDK and runtime, plus pre-installed FFmpeg. AI models (Whisper, Flan-T5) are packaged as volumes or downloaded on first startup. The Next.js frontend is served from a separate container. Everything orchestrated with docker-compose for development and production.
Technologies Implemented
frontend
backend
ai And Media
tools
System Gallery